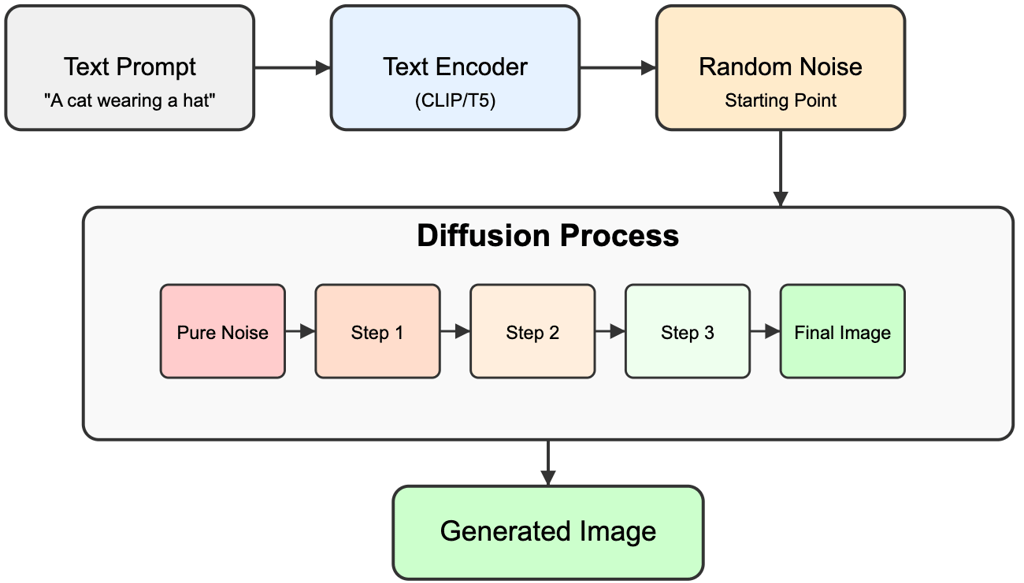
How i2t Gen Work
1. Diffusion Models



Destructive Process
Slowly Maps Data to noise


Diffusion Models


2. Text-Image Pairs
A person in a decorative hat with blue feathers looking over their shoulder against a warm-toned background.
________________________________________________
________________________________________________
________________________________________________
Cream-colored kitten with blue eyes on leopard print fabric.

________________________________________________


Stable Diffusion --> over 2.3 billion image-text pairs
Diffusion model is trained to map noise back to data
Two key concepts
Step 1: Destruction Process – AI first learns how to turn an image into noise.
Step 2: Reverse Process – AI learns to rebuild the image from noise using patterns.
Step 3: Generating New Images – AI starts from random noise and "paints" the image step by step.
1980, cinematic still from a vintage film, two stylishly dressed women sit in a grand retro movie theater, staring directly at the camera while watching a flickering film on the big screen. Neon reflections and dim theater lighting cast a nostalgic glow on their faces. One woman has voluminous permed hair, the other has sleek, straight blonde hair, both wearing bold 1980s fashion--one in a shoulder-padded power suit, the other in a silky blouse with dramatic accessories. The grainy film texture and soft glow capture the essence of classic 80s cinema, evoking the magic of the theater experience